블룸 필터는 요소를 빠르게 조회할 수 있는 데이터 구조입니다. 고정 된 길이의 0과 1의 배열을 포함하는 비트 벡터입니다. 공간과 시간의 효율성이 뛰어난 것으로 알려져 있습니다.
부인 성명 한국어 실력이 부적하여 이 글이 구글 번역기를 주로 활용했기 때문에 부정확한 문법과 어휘가 있을수 있습니다. 이 점 양해 부탁드리며, 추후에 다시 검토하여 수정하도록 하겠습니다.
검색 키워드 캐싱 및 취약한 비밀번호 감지와 같이 중요하지 않은 데이터를 조회하는 데 유용한 것은 본질적으로 확률적입니다. 이 필터는 검색있을때 응답으로 "확실 아니요" 또는 "아마도"만 반환합니다.
대답이 "아마도"인 경우 구선된 허용된 오탐룰을 기반으로 데이터가 실제로 거기에 있을 가능성이 높습니다. 대답이 "아니요"이면 데이터가 세트에 확실히 존재하지 않은 것입니다. 즉, 플룸 필터는 거짓 긍정(타입 I 오류)을 얻을 가능성이 낮은 확률을 가질 수 있지만 거짓 부정은 절대 없습니다.
다음은 데모용으로 크기가 10인 간단한 블룸 필터입니다.
작동하는 방법
블룸 필터에 항복을 추가하려면 입력을 가져와 몇 가지 해시 함수로 해시하여 여러 해시 다이제스트를 얻습니다. 그 다음에, 결과는 뒤집힐 비트의 위치를 결정하는 데 사용됩니다.
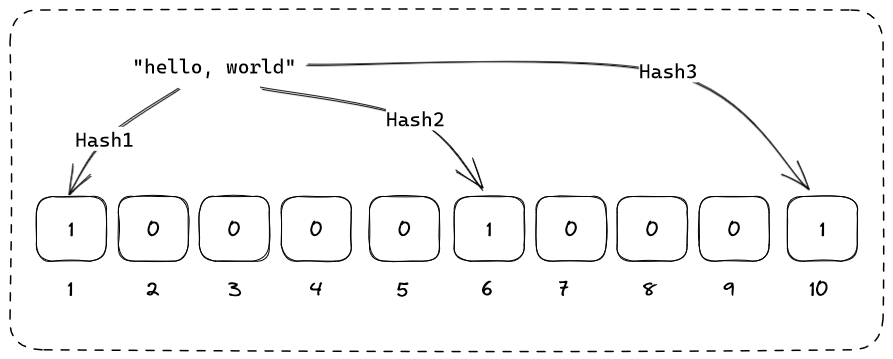
여기서는 hello, world 문자열을 가져와 3개의 서로 다른 독립적인 해시 함수로 해시하고 그에 따라 비트를 뒤집습니다.
그 후 쿼리가 동일한 값을 조회하려고 하면 생성된 해시는 동일하고 결과는 이미 뒤집힌 동일한 비트를 가리키며 항목이 있을 가능성이 매우 높다는 것을 나타냅니다.
문자열 hi, mum을 쿼리하고 동작을 관찰해 보겠습니다.
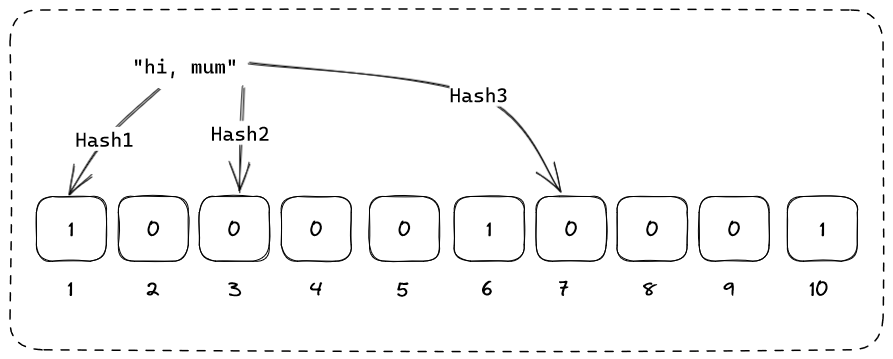
결과에 따르면 Hash1만 일치하는 반면 Hash2와 Hash3은 모두 일치하지 않습니다. 그러므로 hi, mum는 확실히 존재하지 않는다는 것을 추론할 수 있습니다.
충돌
블룸 필터의 항목 수가 증가할수록 더 많은 비트가 뒤집어지고 충돌이 발생하기 마련입니다. 존재하지 않는 입력이 주어지면 모든 해시 함수의 결과가 뒤집힌 비트를 가리키게 되어 잘못된 긍정 결과가 생성될 수 있으며 이것이 블룸 필터가 확률적 데이터 구조로 간주되는 이유입니다.
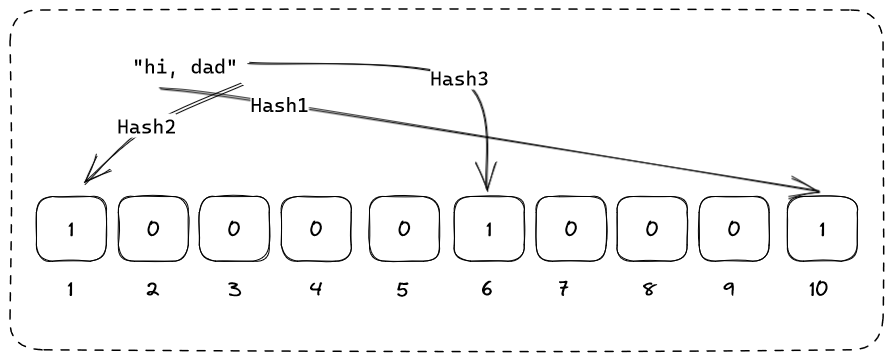
문자열 "hi, dad"의 해시가 우연히 앞서 "hello, world"에 의해 반전된 비트로 떨어지며 이는 거짓양성이 어떻게 나타날 수 있는지를 보여줍니다.
좋은 소식은 매개변수를 적절하게 조정하면 사용 사례에 허용될 만큼 충분히 낮은 임계값까지 위양성 비율을 최소화할 수 있다는 것입니다.
매개변수
제어할 수 있는 매개변수.
| 매개변수 | 설명 | |
|---|---|---|
| 1. | 비트 배열, | 블룸 필터의 크기 |
| 2. | 해시함수 수, | 사용된 해시 함수의 수 |
| 3. | 현재 개수, | 삽입된 총 항목 수 |
| 4. | 거짓양성 확률, | 오탐률 |
매개변수들은 간의 관계는 다음과 같은 수식으로 표현될 수 있습니다.
위양성의 확률은 삽입된 항목 수에 직접적으로 비례하므로
해시 함수의 개수
그러나 사용되는 해시 함수의 수는 요소를 삽입할 때 더 많은 비트를 차지하고 결과적으로 충돌 가능성이 높아지므로 블룸 필터의 효율성과 일치하지 않습니다. 실제로 더 많은 해시 함수를 사용할수록 작업 실행 속도가 느려집니다.
샘플 구현
이는 JavaScript의 가단한 구현입니다. Python 구현에 대해서는 Brilliant.org를 참조하세요.
var crypto = require("crypto");
class BloomFilter {
#size;
#sliceStart;
#sliceEnd;
#array;
#itemCount = 0;
get itemsAdded() {
return this.#itemCount;
}
constructor(size = 50, sliceStart = 0, sliceEnd = 4) {
this.#size = size;
this.#sliceStart = sliceStart;
this.#sliceEnd = sliceEnd;
this.#array = new Array(size);
}
insert(string) {
var [hash1, hash2, hash3, hash4] = this.#getHashes(string);
this.#array[
Number("0x" + hash1.slice(this.#sliceStart, this.#sliceEnd)) % this.#size
] = 1;
this.#array[
Number("0x" + hash2.slice(this.#sliceStart, this.#sliceEnd)) % this.#size
] = 1;
this.#array[
Number("0x" + hash3.slice(this.#sliceStart, this.#sliceEnd)) % this.#size
] = 1;
this.#array[
Number("0x" + hash4.slice(this.#sliceStart, this.#sliceEnd)) % this.#size
] = 1;
this.#itemCount++;
}
find(string) {
var [hash1, hash2, hash3, hash4] = this.#getHashes(string);
return !!(
this.#array[
Number("0x" + hash1.slice(this.#sliceStart, this.#sliceEnd)) %
this.#size
] &&
this.#array[
Number("0x" + hash2.slice(this.#sliceStart, this.#sliceEnd)) %
this.#size
] &&
this.#array[
Number("0x" + hash3.slice(this.#sliceStart, this.#sliceEnd)) %
this.#size
] &&
this.#array[
Number("0x" + hash4.slice(this.#sliceStart, this.#sliceEnd)) %
this.#size
]
);
}
showState() {
console.log("현재 상태: ", this.#array);
}
#getHashes(str) {
var hash1 = crypto.createHash("sha1").update(str).digest("hex");
var hash2 = crypto.createHash("sha256").update(str).digest("hex");
var hash3 = crypto.createHash("mdc2").update(str).digest("hex");
var hash4 = crypto.createHash("sha384").update(str).digest("hex");
return [hash1, hash2, hash3, hash4];
}
}문자열은 insert 메서드를 통해 삽입할 수 있습니다. find 메서드는 부울 값을 반환하는 조회 작업에 사용됩니다. showState 메소드는 비트 배열의 현재 상태를 표시합니다. #itemCount는 인스턴스화 이후 삽입된 요소 수를 추적합니다.
#sliceStart 및 #sliceEnd는 블룸 필터와 아무 관련이 없습니다. 이는 제가 개인적으로 해시를 해석하고 이를 비트 배열 위치로 변환하는 데 사용하는 방법일 뿐입니다.
결론
간단히 말해서, 블룸 필터는 거짓 긍정이 허용될 수 있는 상황에서 사용할 수 있는 강력하고 효율적인 데이터 구조입니다. 희박한 충돌 가능성을 허용함으로써 우리는 아주 작은 크기의 믿을 수 없을 만큼 메모리 효율적인 데이터 구조를 얻게 됩니다.